Text-to-Speech vs Human Narration: Which Is Better?
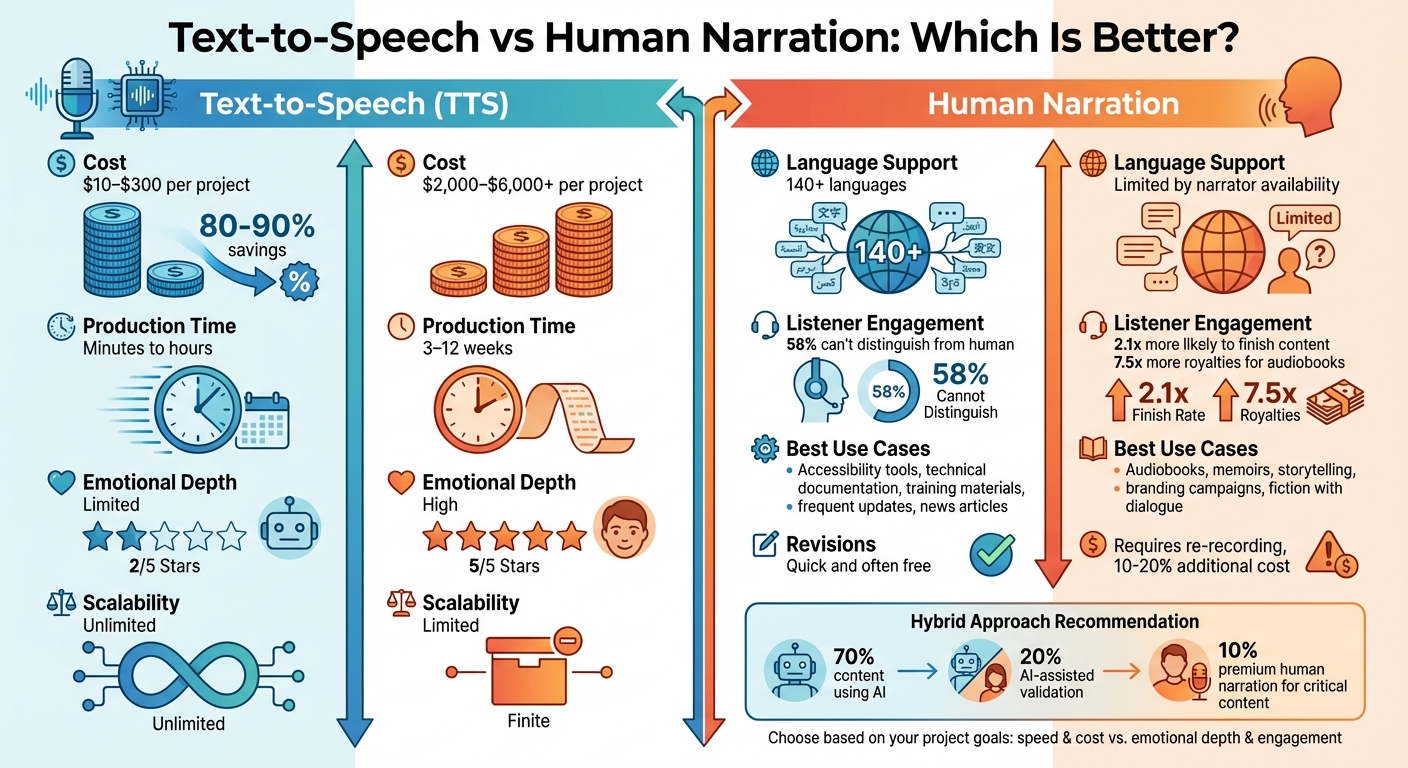
Choosing between text-to-speech (TTS) and human narration depends on your goals: speed and cost versus emotional depth and listener engagement. TTS is fast, scalable, and budget-friendly, making it ideal for projects like technical content, training materials, or accessibility tools. Meanwhile, human narration offers emotional nuance and performance, perfect for audiobooks, storytelling, or branding campaigns.
Key Highlights:
- TTS Pros: Produces audio in minutes, costs $10–$300 per project, and supports over 140 languages.
- Human Narration Pros: Delivers emotional depth, increases listener engagement, and generates 7.5x more royalties for audiobooks.
- Costs: Human narration ranges from $2,000–$6,000 per project, while TTS costs are 80–90% lower.
- Production Speed: TTS completes audio in hours; human narration takes 3–12 weeks.
- Scalability: TTS handles large-scale projects effortlessly; human narration is limited by time and availability.
Quick Comparison:
| Factor | Text-to-Speech (TTS) | Human Narration |
|---|---|---|
| Cost | $10–$300 | $2,000–$6,000+ |
| Production Time | Minutes to hours | 3–12 weeks |
| Emotional Depth | Limited | High |
| Scalability | Unlimited | Limited |
| Best For | Accessibility, technical content, updates | Audiobooks, storytelling, branding |
For most projects, a hybrid approach — using TTS for efficiency and human narration for high-impact content — provides the best balance between cost, quality, and engagement.
Human vs. AI: Who Should Narrate Your Audiobook in 2025?
What Is Text-to-Speech Technology?
Text-to-speech (TTS) technology transforms digital text — like documents, web pages, or scripts — into spoken audio. Over the years, it has progressed significantly, moving beyond the monotone, robotic voices of the past. Thanks to neural TTS systems powered by deep learning, modern speech synthesis now delivers audio that sounds almost indistinguishable from a human voice.
The process of TTS involves three main steps. First, the system cleans and normalizes the input text, handling tasks like expanding abbreviations (e.g., turning "Dr." into "Doctor") and converting numbers into words. Next, it performs linguistic analysis, breaking the text into phonemes and assigning stress, intonation, and pauses. Finally, an acoustic model generates a representation of the speech, which a vocoder then converts into sound.
"You can't have somebody producing a new audio version of one article every time it's updated. But with synthetic language, there's hardly any additional cost to production at all." – Andy Webb, Head of Product for Voice and AI, BBC
Core Features of TTS
Modern TTS systems excel in handling complex linguistic nuances, providing accurate pronunciation and maintaining consistent, high-quality audio output. They can resolve tricky issues like distinguishing between homographs — such as "read" (present tense) and "read" (past tense) — while ensuring a stable "house voice" across different sessions.
Another key strength is speed. TTS generates audio almost instantly, making it ideal for real-time applications like conversational interfaces or quick content updates. For example, platforms like TTSBuddy support over nine languages and offer a library of more than 50 voices, allowing users to choose options that align with their specific needs. TTSBuddy also includes tools like Web Buddy for voice-based website interaction, Doc Buddy for converting documents into audio, and Offline Buddy for accessing content without an internet connection. An upcoming API Buddy feature is designed to handle large-scale text-to-audio conversions for enterprise projects.
Benefits of TTS
TTS technology overcomes many limitations of traditional human narration. It offers unmatched scalability, enabling the creation of extensive audio libraries — such as entire collections of articles or training modules — without the delays associated with recording sessions. This is especially valuable given that 73% of content teams struggle to keep materials updated.
Another major advantage is cost. Hiring a professional voice actor to narrate a 750-word article can cost around $749. In contrast, TTS requires only a software subscription or a usage-based API fee, making it a far more budget-friendly option.
TTS also plays a critical role in accessibility. It benefits the estimated 2.2 billion people worldwide with vision impairments or low vision, as well as individuals with dyslexia, cognitive challenges, or limited literacy skills. Beyond accessibility, TTS can be a valuable tool for students and content creators. By listening to their work read aloud, they can catch errors in flow, tone, and structure that might be overlooked during visual proofreading.
These advantages highlight why TTS is increasingly being compared to traditional human narration for a range of use cases.
Why Human Narration Still Matters
While text-to-speech (TTS) technology is fast and scalable, it falls short when content demands emotional depth and contextual nuance. Human narration isn't just about sounding natural — it's about delivering a performance. A skilled narrator brings life, emotion, and meaning that machines can't fully replicate.
"The narrator understands not just the definition of the words they're saying, but the emotion and history behind them. They know the difference between a sigh of relief and a sigh of resignation." – Eric Hal Schwartz, Contributor, TechRadar
This ability to deliver nuanced performances makes human narration stand out. For example, audiobooks narrated by humans generate, on average, 7.5 times more royalties compared to AI-narrated ones. Moreover, listeners are 2.1 times more likely to finish an audiobook when the narration is emotionally engaging rather than robotic. A 2024 survey found that 67% of content creators prioritize "naturalness" over cost or features when choosing narration methods.
Emotional Expression and Natural Delivery
Human narrators excel at capturing the subtle emotional undertones that AI struggles to convey authentically. Imagine an author narrating their own memoir — when their voice trembles during a painful memory, it creates an intimacy that synthetic voices simply cannot achieve. Professional narrators also use pacing, tone, and pauses to highlight meaning. For instance, videos with emotionally expressive narration hold viewers' attention 34% longer than those with monotone delivery.
While modern TTS systems can simulate emotions using tags like [whispering] or [angry], they often miss the deeper context. Even the most advanced AI can produce rhythm or tone inconsistencies that feel unnatural to listeners. Human narrators, on the other hand, bring an intuitive understanding of emotional nuance, creating a more immersive experience.
Adjusting to Different Content Types
Another key strength of human narrators is their ability to adapt their delivery to match the specific needs of different content. For children's stories, they use playful tones and dynamic pacing to keep young listeners engaged. In thrillers or romance novels, they build tension and excitement through dramatic timing and distinct character voices. Memoirs, on the other hand, benefit from the authenticity and personal connection that only a human voice can provide.
"Human narrators bring life experience, expression, and emotional nuance... [they] are better equipped to pick up on idioms, tone shifts, and culturally appropriate phrasing." – LanguageLine
This adaptability is especially important for complex narratives with multiple perspectives or unreliable narrators, where tone and subtext play a critical role. Professional voice actors can adjust their delivery, improvise, and respond to direction, ensuring the narration aligns perfectly with the content's intent. They also handle idioms, cultural references, and regional accents with a level of understanding that AI often misinterprets. For high-stakes projects like bestselling novels or premium marketing campaigns, human narration continues to set the standard, offering a level of artistry and emotional connection that justifies the investment.
TTS vs Human Narration: Side-by-Side Comparison
Text-to-speech (TTS) technology and human narration each bring their own advantages and challenges. Deciding between them depends on your priorities — whether it's cost, emotional depth, or production speed.
AI narration can reduce recording expenses by 80%–90%, making it a highly cost-effective option. On the other hand, human narrators bring a level of emotional resonance that translates into 7.5 times more royalties. This highlights the trade-off between efficiency and the immersive experience only humans can deliver.
"One version delivers information. The other creates experience." – Roy Samuelson, Audio Description Performer
Interestingly, studies reveal that 58% of listeners now struggle to differentiate AI-generated voices from human ones. While TTS technology has improved dramatically, it still falls short in capturing the subtle nuances — like pauses, tone shifts, and emotional depth — that human narrators naturally convey.
Here's a closer look at how TTS and human narration compare across key factors:
Comparison Table
| Factor | Text-to-Speech (TTS) | Human Narration |
|---|---|---|
| Voice Naturalness | Clear and stable; may sound robotic in long segments | Natural rhythms, intentions, and breathing |
| Emotional Expression | Improving, but struggles with humor and subtle subtext | High; evokes empathy and handles micro-expressions |
| Cost | $10–$300 per project; far cheaper than human | $2,000–$8,000+ per project |
| Production Speed | Minutes to hours | 3 to 12 weeks |
| Scalability | Unlimited and instant | Limited by narrator availability |
| Accessibility | High; ideal for low-budget projects | High; fosters inclusivity and belonging |
| Revisions | Quick and often free | Requires re-recording and additional costs |
Both options have their place, depending on the goals of your project. Whether you prioritize affordability or emotional impact, understanding these differences helps you make the right choice for your audience.
Cost and Scalability Analysis
Price Comparison
The cost difference between AI narration and human voice work is striking. For an 80,000-word audiobook — approximately 8 to 9 hours of finished audio — human narration typically ranges from $2,400 to $6,000 or more. In contrast, the same project using AI narration costs only $40 to $250. Professional human narrators charge between $0.03 and $0.08 per word, while AI narration often costs less than $0.001 per word. For example, TTSBuddy offers a premium plan at just $15 per million characters, making it an incredibly cost-efficient option.
In addition to the narrator's fee, human production comes with extra costs. These often include hiring a voice director ($200–$600), a proofing service ($150–$400), and a pronunciation consultant for technical or specialized content ($100–$300). Re-recordings, often necessary, can increase total expenses by 10% to 20% due to studio and session fees. On the other hand, AI narration allows for near-instant revisions, usually included within the standard pricing structure.
"The cost ratio runs between 10:1 and 30:1 in favor of AI narration." – Narration Box
While cost savings are a major factor, the ability to scale production quickly is equally transformative.
Scaling and Production Speed
AI narration doesn't just save money — it also drastically reduces production time. Converting a 70,000-word manuscript to audio with AI takes less than an hour, compared to the 6-to-12-week timeline required for human narration. Human production involves about 3.5 hours of recording and editing for every finished hour of audio. This efficiency enables independent authors to release 3 to 7 times more titles per year, cutting production timelines from weeks to mere hours.
AI narration is especially useful for large-scale projects like web accessibility and educational content. For instance, it can generate 100 e-learning voice clips in just minutes, a process that would take days with human narrators. Additionally, AI supports global expansion effortlessly, offering 140+ languages and regional accents without requiring separate voice actors for each market.
"You can't have somebody producing a new audio version of one article every time it's updated. But with synthetic language, there's hardly any additional cost to production at all." – Andy Webb, Head of Product for Voice and AI, BBC
This combination of speed and global reach makes AI narration an invaluable tool for scaling content across diverse markets efficiently.
When to Use TTS or Human Narration
Choosing between AI-generated text-to-speech (TTS) and human narration depends on factors like content type, budget, and audience expectations. It's about striking a balance between cost and speed versus emotional depth and context. Both approaches offer unique advantages for increasing accessibility and audience engagement.
Best Uses for TTS
AI narration is all about efficiency, scalability, and consistency. For instance, news outlets leverage TTS to deliver audio versions of breaking stories almost instantly. As BBC's Andy Webb highlighted, synthetic voices remove the need to re-record audio every time an article is updated.
TTS is especially practical for technical documentation and training materials, where frequent updates are common. You can simply edit the text and regenerate audio without the hassle of a full re-recording. This makes it ideal for software tutorials, compliance training, and interactive voice response (IVR) systems.
Long-form content, like audiobooks exceeding 100,000 words, also benefits from TTS. It ensures consistent voice quality over lengthy recordings, something human narrators might struggle with due to voice fatigue. With premium TTS plans, entire backlists of manuscripts can be converted into audio cost-effectively. Plus, with support for 9+ languages and over 50 voice options, TTS enables global reach without hiring multiple voice actors.
Accessibility is another area where TTS shines. Tools like TTSBuddy's Chrome extension and offline audio options make it easier for users to consume web content and documents in ways that suit their needs.
However, for content that demands emotional storytelling, human narration remains the better choice.
Best Uses for Human Narration
When emotional depth and authenticity are critical, human narration takes center stage. Fiction with intricate dialogue, multiple perspectives, or rich emotional layers is best served by a skilled human voice actor. Similarly, memoirs and personal stories gain an intimate touch when narrated by the author or a professional who can capture their essence.
Human narration also excels in high-stakes branding and storytelling. For flagship campaigns or sonic branding, a warm, personal voice can resonate far more effectively with audiences. As Ernst-Jan Pfauth, CEO of The Correspondent, put it:
"With audio, it's even more personal than text, and we see more opportunities there because it's a more intimate way of consuming journalism."
Many publishers now adopt a hybrid approach, often referred to as the "10% premium rule." They reserve human narration for their top-performing titles and bestsellers, while relying on AI narration for the rest of their catalog.
Conclusion: Choosing the Right Option
Based on the comparisons outlined earlier, the best choice ultimately depends on how well your project's goals align with the advantages of each approach.
AI narration is a cost-effective option. For instance, a typical non-fiction audiobook narrated by a human can cost anywhere from $2,000 to $7,000. In contrast, AI voice-over services usually fall between $10 and $50 per project. This makes AI a practical choice for those working within tight budgets.
When it comes to large-scale or time-sensitive audio production — think technical content or frequent updates — text-to-speech (TTS) technology stands out. However, for projects where emotional nuance is critical, such as memoirs, literary fiction, or high-profile branding campaigns, human narration remains unmatched.
Accessibility is another important factor to consider. TTS plays a vital role in supporting the 2.2 billion people worldwide living with visual impairments, as well as individuals with dyslexia or ADHD. Tools like TTSBuddy, which offer a Chrome extension, offline audio options, and support for over nine languages, simplify accessibility without the logistical hurdles of managing human narrators.
Many creators are now blending both methods. A popular approach is the "70-20-10" model: 70% of content is produced using AI, 20% is validated with AI assistance, and the top 10% — the most critical or nuanced material — receives full human narration. This hybrid strategy balances efficiency with quality. As Andy Webb from the BBC pointed out:
"You can't have somebody producing a new audio version of one article every time it's updated. But with synthetic language, there's hardly any additional cost to production at all."
Ultimately, the decision boils down to your project's priorities. Whether your focus is on saving costs, delivering emotional depth, speeding up production, or improving accessibility, aligning your needs with the strengths of each method will guide you to the right choice.
FAQs
How do I choose between TTS, human narration, or a hybrid?
Choosing the right voice solution — TTS (Text-to-Speech), human narration, or a hybrid approach — comes down to your goals, budget, and the emotional tone you want to convey.
- TTS works best for projects that need scalability and cost-efficiency, such as training modules or accessibility tools. Modern TTS voices sound natural and can handle large volumes quickly.
- Human narration shines when the goal is to evoke emotion or deliver a premium storytelling experience. It offers a level of authenticity and depth that's hard to replicate.
- A hybrid approach blends the strengths of both: using TTS for high-volume tasks while reserving human narration for sections that require a personal, nuanced touch.
Each option has its place, so the choice depends on what your project demands most.
Will listeners notice if I use AI text-to-speech?
Modern AI text-to-speech systems are so advanced that they sound incredibly natural and realistic. In fact, most people can't tell the difference between an AI-generated voice and a human one unless they listen closely or actively look for subtle cues. That said, human voices still tend to be the go-to choice for content that requires emotional depth or storytelling, as they bring a level of connection and sincerity that's hard to replicate. Even so, AI voices serve as a practical and convincing option for many applications.
What should I consider before using TTS for accessibility?
When incorporating text-to-speech (TTS) for accessibility, pay close attention to the voice quality. It should sound natural, articulate clearly, and convey some level of emotional expression to ensure a better listening experience. Make sure the technology complies with accessibility standards, such as WCAG guidelines, to meet the needs of all users. Transparency is also key — let your audience know when TTS is being used to maintain their trust.
Keep in mind that TTS often lacks the emotional depth of a human narrator. Because of this, it's important to assess whether it aligns with your audience's preferences and works well for your specific use case.